
前言
上篇博客讲了如何集成gitalk,如果你还不会集成gitalk 点击这里 快去集成你的gitalk吧,上次我们还有一个问题没有解决,那就是每次发文之后,需要手动的去初始化gitalk,就去抓了一下gitalk初始化发送的网络请求,自己写一个脚本来实现自动初始化,你也可以嵌到你的博客系统里,每次发新的文章都自动进行初始化,下面我们来看,如何实现。
正文
在使用脚本之前,你需要获取一个权限,Personal access tokens在当前页面为Token添加所有的repo权限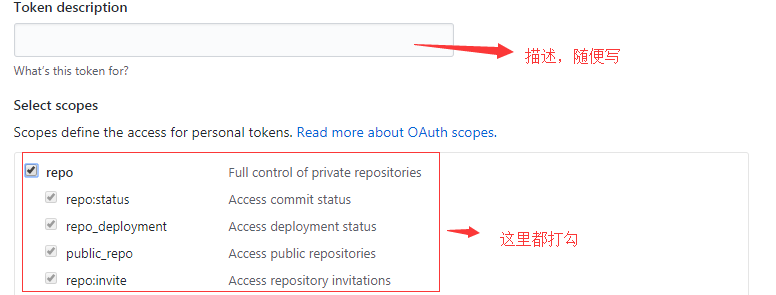

这样就获取到了Token,之后我们来看代码
python版本:
# -*- coding:utf-8 -*- |
java版本:
import org.apache.http.HttpResponse; |
上面的python版本和java版本,分别能初始化自己的博客评论,我的是将代码放到了发布文章的时候,自动初始化。
上面只是解决的,单个文章的问题,如果之前是其他评论系统,现在改用gitalk的,那岂不是需要一个个的执行。
因为我的博客比较简单,我就自己顺手写个批量初始化的,其实就是爬取文章的uri和title然后调用单个的初始化脚本,我的脚本如下:
import requests |
这个脚本只是适合我自己的博客,如果要其他博客也用的话,需要根据自己的实际情况更改xpath的值。
##结语
之前刚接触Gitalk的时候,网络上自动化的初始脚本都是ruby,对于我这个学渣来说,只能看个大概,无奈,只能自己写了,好了,希望这篇文章对你们有帮助,下面附上git的自动化gitalk的地址。
源码地址:戳这里